What this is.
Experience + Opinion + Fact (50% experience · 30% opinion · 15% fact · 5% fiction)
Written in collaboration with AI — I discuss, I do not outsource.
Every few months, I watch a team spend weeks debating FreeRTOS vs Zephyr. They compare tick rates, memory footprints, community size, licensing. They build evaluation boards. They write comparison docs. Eventually someone makes the call. Then they ship the product, and the same structural problems show up that the comparison doc never even named. Different logo on the box 📦. Same headache in the codebase.
Chapter 1. The Question Everyone Debates
The RTOS-comparison ritual is something I have watched at startups, factories, and Fortune 500 firmware teams alike. It looks productive. It feels like rigor.
A team forms. A senior engineer takes the lead. A spreadsheet appears with rows for each candidate — FreeRTOS, Zephyr, ThreadX, NuttX, sometimes Micrium. Columns for tick rate, memory footprint, community size, license terms, vendor support, BSP availability for the target MCU.
They build evaluation boards. They prototype the same small example on each one. They write a comparison doc. After a few weeks, someone makes the call.
Then the team starts shipping. And the structural problems that show up six months later have nothing to do with the choice they spent six weeks making.
▸ First principle. When the loudest decision feels productive, that is often a sign it is masking the quieter one that actually matters.
The decision that the loud one masks is what the next chapter is about.
Chapter 2. The Question Nobody Asks
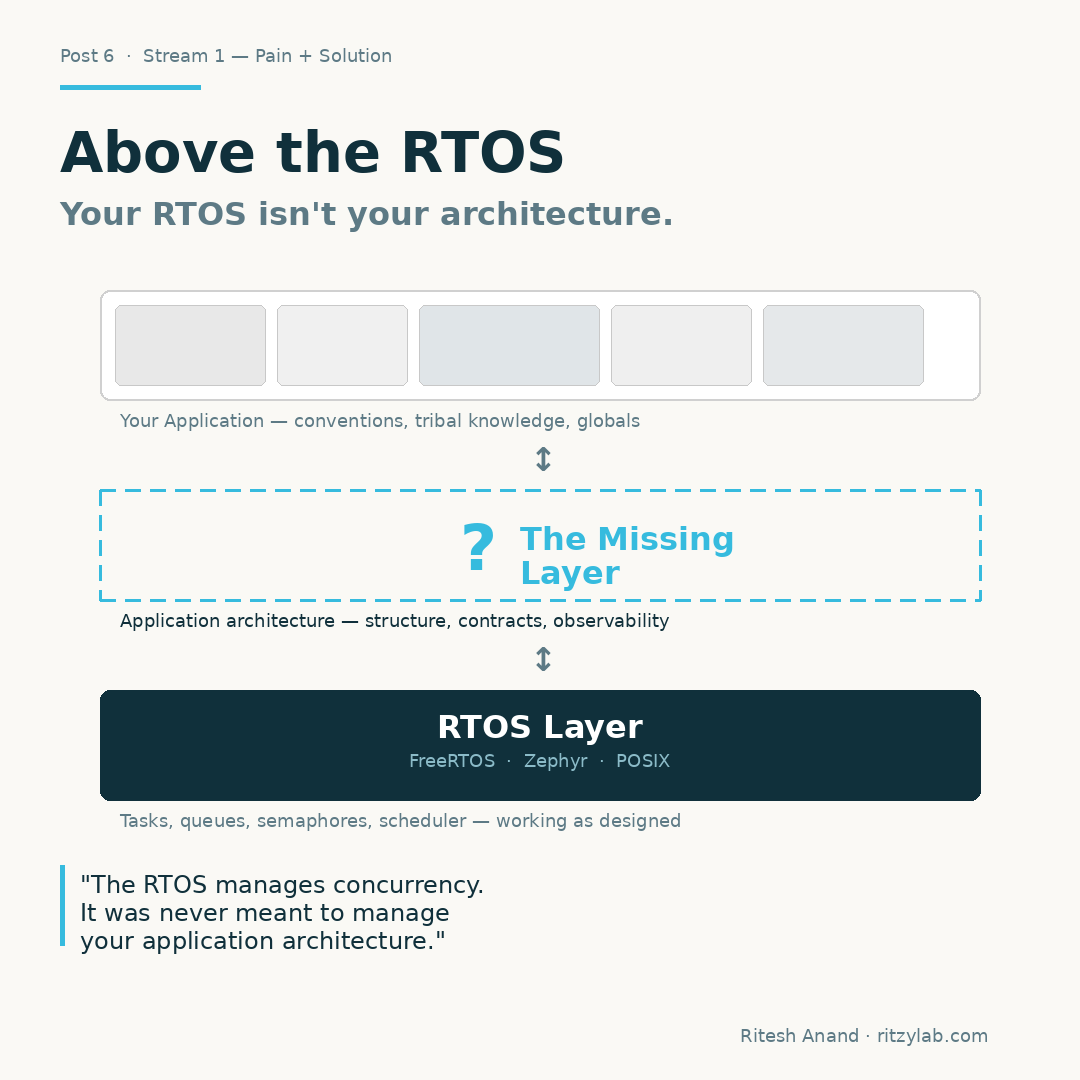
An RTOS gives you tasks, semaphores, queues, and a scheduler. That is its job. It manages concurrency and timing. Useful — necessary, even. But it does not tell you anything about how your application is structured.
It does not define how your sensor task talks to your comms task. It does not enforce boundaries between subsystems. It does not prevent one module from reaching into another module's state.
That is not the RTOS's job. That is the architecture's job. And most embedded projects do not have a formal one. What they have is conventions — a lead engineer who carries the system map in their head, a naming scheme, maybe a block diagram drawn during the first sprint that nobody updated since.
That works for a while. Then the team grows. Or the product ships and field bugs come in. Or you port to a new MCU and discover that your "architecture" was really just assumptions wired to a specific BSP.
The architecture decision was made. It was just made implicitly, by accumulating habit, with no one writing it down. The team picked an RTOS rigorously. They picked an architecture by default.
▸ First principle. Every embedded project has an architecture. The only question is whether you designed it or you accumulated it.
What an accumulated architecture costs is the next chapter.
Chapter 3. The Cost of Implicit Architecture
I have worked on products where a state machine in one module was reading a global variable set by an ISR in a completely different module. No contract between them. No typed interface. Just a shared volatile and a convention that both sides understood.
Nobody wrote that to be reckless. It was the pragmatic shortcut when there is no framework enforcing a better pattern. And it works — until it does not.
The version where it stops working is always specific. A new engineer joins and does not know about the convention. The ISR's timing changes when you bump the MCU clock. A second consumer needs the same data, and now you have two readers fighting over the volatile. The bug shows up in the field, not in the lab. By the time you trace it, three sprints have passed and you have shipped the bug to ten thousand units 🚨.
This is not a story about one project. It is the same story across 40+ products I have worked on across 20+ years of building 🔧. Different teams, different industries, different MCUs. The bug pattern is identical because the structural gap is identical.
▸ First principle. A recurring class of defect is never an engineer problem. It is the architecture telling you that something has been left implicit that should have been explicit.
When I posted about this pattern recently, the conversation that followed surfaced something I had not expected.
Chapter 4. What the Conversation Surfaced
I posted a shorter version of this on LinkedIn a few weeks ago — the same argument, compressed. The replies sharpened it more than the post itself did 🧠.
Three threads stood out.
The "RTOS as library" reframe. One architect put it cleanly: an RTOS is just a library. It belongs inside the application architecture, not above it. Frame it that way and the question "which RTOS?" stops feeling like a load-bearing decision. It is a tool choice, not a foundation.
Sometimes the right answer is no RTOS. Two engineers shared production stories. A digital TV receiver shipped to a major broadcaster running three custom interpreters and no scheduler at all. A multicore SoC running an RTOS on one core and bare-metal on another for a hot data path where even thin OS layers added too much jitter. Different products, same lesson — when the architecture is clear, the question of "which RTOS" sometimes resolves to "none."
Frameworks always need escape hatches. A sharp critique came up: "the problem with having a 'standard' application framework is that there is always a requirement that breaks it." Classic AUTOSAR landed there too, with its complex-drivers mechanism that lets you go almost bare-metal when the framework gets in the way. This is correct, and it is the part most framework attempts get wrong. A useful application layer has to plan for the requirement that does not fit — not pretend that requirement will never exist.
I read all three threads as the same point in different framings: the loud question is the wrong one, and the right one is what shape your application takes regardless of what runs underneath it.
▸ First principle. A good public post is a hypothesis. The replies are how you find out which parts were right and which parts were lazy.
One more thing the conversation surfaced. It required me to be honest about prior art.
Chapter 5. Honest Prior Art
I formed this approach independently, after 20+ years of seeing the same pattern across 40+ products. After I committed to it, I researched whether others had done versions of the same thing. They had.
The closest prior work is Active Objects, formalized in QP/C since 2005 — shared-nothing, event-driven, non-blocking inside each block. Same impulse, different solution. Mine is RTOS-agnostic, observability-first, and built specifically with AI agents in mind as future participants in the codebase 🤖.
There are others worth naming. Classic AUTOSAR addresses a parallel problem in automotive — a heavy-weight standardized framework with the complex-drivers escape hatch already mentioned. Infuse-IoT is a more recent stack from a fellow builder, narrower in scope (Zephyr-only, ultra-low-power IoT) but solving the same "missing layer" problem inside that niche. OSAL patterns and POSIX-style abstraction layers have lived in industry for decades — they fix the OS-portability part of the problem but stop short of the application-architecture part.
The honest read is: multiple builders, working independently, kept arriving at the same conclusion that the layer above the RTOS was the one no one had standardized. The convergence is the signal.
▸ First principle. When you arrive at an idea independently and then find that others have arrived at versions of it too, you are not late. You are corroborated.
Why this layer never standardized in embedded — and why web figured it out decades ago — is what is next.
Chapter 6. Web Got This Decades Ago. Embedded Did Not.
Nobody builds a production web app today by wiring raw HTTP handlers to global state. You use a framework — React, Rails, Django, Express, Next. The framework enforces structure. Your code plugs into it. The framework decides how routes are organized, how state is managed, how requests are middleware'd, how observability is wired in.
Embedded never got that layer. We got great RTOSes. We got HALs. We got BSPs. The application layer — the thing that defines how firmware modules are structured, how they communicate, how they are observed — has been left to each team to reinvent. Every project. From scratch. With the same structural problems emerging at scale.
Why? A few reasons. Embedded systems are heterogeneous in a way web apps are not — different MCUs, different RTOSes, different memory budgets, different real-time constraints. A framework that locks you to one tier alienates the others. Embedded teams are also smaller, with less appetite to standardize across products that ship to different customers. And until recently, embedded did not have the AI tailwind that made structured code valuable in a new way 🤖.
The last point matters a lot. AI agents write React reliably because the framework is well-described. Routes are typed. State is managed. Components have clear contracts. An AI can plug into that and produce code that mostly works. Embedded has been the opposite — every codebase is a custom snowflake, and an AI agent has to relearn the conventions every time. That is the part of the gap I started caring about most.
▸ First principle. Frameworks are not a productivity hack. They are how the next builder — human or AI — joins your team without three months of onboarding.
The layer I have been building is what closes that gap.
Chapter 7. The Missing Layer
For the last few years I have been quietly building the application layer above the RTOS — RTOS-agnostic, observable from day one, designed to be readable by both humans and AI agents from the first commit ✨.
Not another RTOS. Not a HAL. Not a BSP replacement. The thing that sits above all of those. Modules with clear ownership boundaries. Typed interfaces between them. State that lives in one place per FSM. Events as the primary communication primitive. Telemetry hooks designed in, not bolted on.
The architecture has held across every codebase I have tested it against. The bug patterns I described in Chapter 3 — the implicit globals, the ownership ambiguities, the state-machine drift — they do not show up. Not because the engineers are smarter. Because the structure of the code makes the wrong path harder to write than the right one.
It is open-source-ready, with escape hatches for the AUTOSAR-style "this requirement breaks the framework" case. External components can plug in for the parts that do not fit the standard pattern. The framework gives you a default; you keep the freedom to step outside when reality demands it.
I am not announcing it yet. The architecture is clear; the implementation is still ripening 🛠️. When it is ready for public use, I will say so explicitly. Until then, the thinking is what I am sharing.
▸ First principle. The fastest way to validate an architecture is to write the post, watch which arguments hold under public scrutiny, and trust that the build is easier from there.
If you are starting a new firmware project this quarter, here is what I would have you decide before you compare a single RTOS.
Architecture-First, RTOS-Second
Four questions to answer before the RTOS choice 📐:
1. What are the modules in this system, and what is the contract between them? Name each subsystem. Describe what it owns. Define the typed interface it exposes. If two modules talk through a shared volatile, you do not have a contract — you have a habit.
2. Where does state live? Pick one place per piece of state. State scattered across modules is state that drifts. State held in one module behind a clear interface is state you can reason about.
3. How do modules communicate? Events, messages, shared memory? The choice locks in coupling. Events with typed payloads scale; raw shared state does not. Make the choice explicit, write it into the architecture doc, and enforce it in code review.
4. How will you observe this in production? Logging, telemetry, debug hooks designed in from day one — not bolted on after the first field bug. If you cannot see what your firmware is doing on a customer's bench, you will be debugging by guesswork at 2 a.m. on a factory floor 🏭.
When the answers to those four are clear, the RTOS choice becomes mechanical. You pick whichever scheduler supports the architecture you have already designed. FreeRTOS, Zephyr, NuttX, ThreadX, even bare-metal — they are all viable when the architecture above them is already explicit.
Pick the Headache Instead
Different logo on the box 📦. Same headache in the codebase. Pick the headache instead, and the box gets simpler 🎯.
Next: why AI can write your frontend reliably but not your firmware — and what that has to do with the layer above the RTOS.
Labeled: Experience + Opinion + Fact + Fiction
(50% experience · 30% opinion · 15% fact · 5% fiction)
Sources:
- Active Objects / QP/C — Practical UML Statecharts in C/C++, Miro Samek (publicly developed since 2005)
- AUTOSAR Classic Platform — Application Architecture & Complex Drivers mechanism
- Mbed OS deprecation announcement — Arm Limited (2024)
- Infuse-IoT (Embeint) — public documentation, Zephyr-based IoT application layer
(Written in collaboration with AI — I discuss, I do not outsource.)
New to this labeling? Read the framework → 20+ Years of Ideas. Articulation Is the Craft.
— Ritesh | ritzylab.com
Stay in the loop
New essays on embedded systems, firmware quality, and engineering craft. No noise.
Discussion
No comments yet. Be the first to share your thoughts.
Leave a comment